In order for IOTA Vue to access data on Databricks - the IOTA Databricks Driver must be configured and deployed on
network
which has access to Databricks. The IOTA Vue uses distributed "mesh-like" data source topology:
Users are free to define what Region and Site mean for their unique deployment.
| Name | Example | Description |
|---|---|---|
| Region | us-east-1 | geographical territory, similar to availability regions |
| Site | siteB | specific plant or a building |
To simplify the installation process, the IOTA Software provides a container image with the latest driver version. The
user is only required to select/create a region and site. Then for the selected driver type, click add a new server.
The container contains all necessary driver's configurations with public and private keys for secure communication
with the company's IOTA Vue NATs message bus.
To access the Data Sources menu, click at the top right corner on the "hamburger" icon, then select "Data Sources".
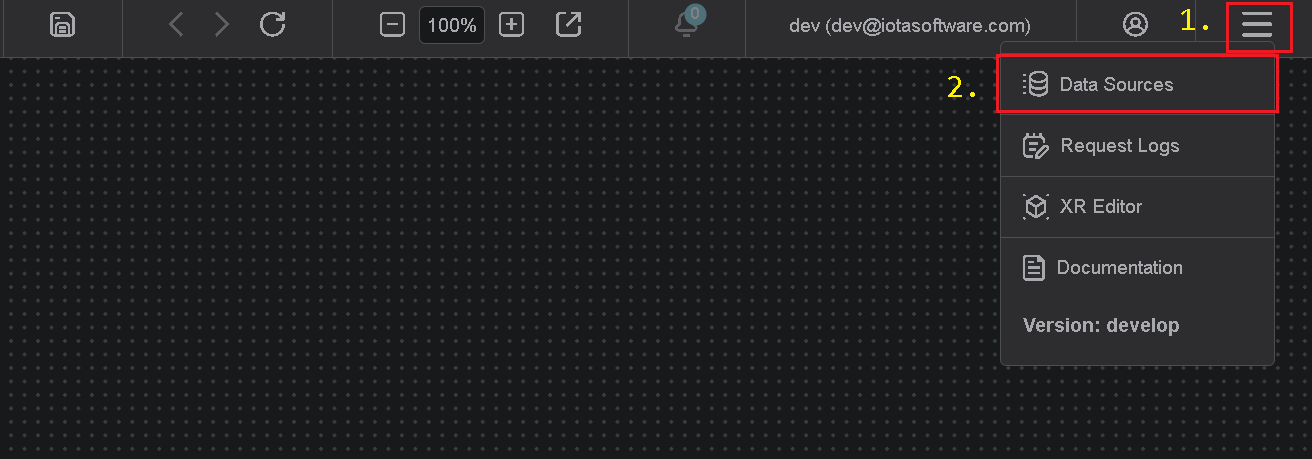
Add Region
Click on the "Add" icon to add a new region, then in the popup dialog - enter the region name.
There are two input fields:
- Region name
- Channel name (optional)
The region name is a user-friendly name, and the channel name can contain abbreviations. If the channel name is not provided, it is automatically assigned to the region name on the "Apply" button click.

Add Site
Click on the "Add" icon to add a new site, then in the popup dialog - enter the site name. Make sure the Generic SQL
checkbox
is selected. Each site can contain multiple driver types. For each checked driver type - the instance pane will contain
selected driver tabs to which connection instances can be added.
There are three input fields:
- Site name
- Driver type
- Channel name (optional)
The site name is a user-friendly name, and the channel name can contain abbreviations. If the channel name is not
provided, it is automatically assigned to the site name on the "Apply" button click.
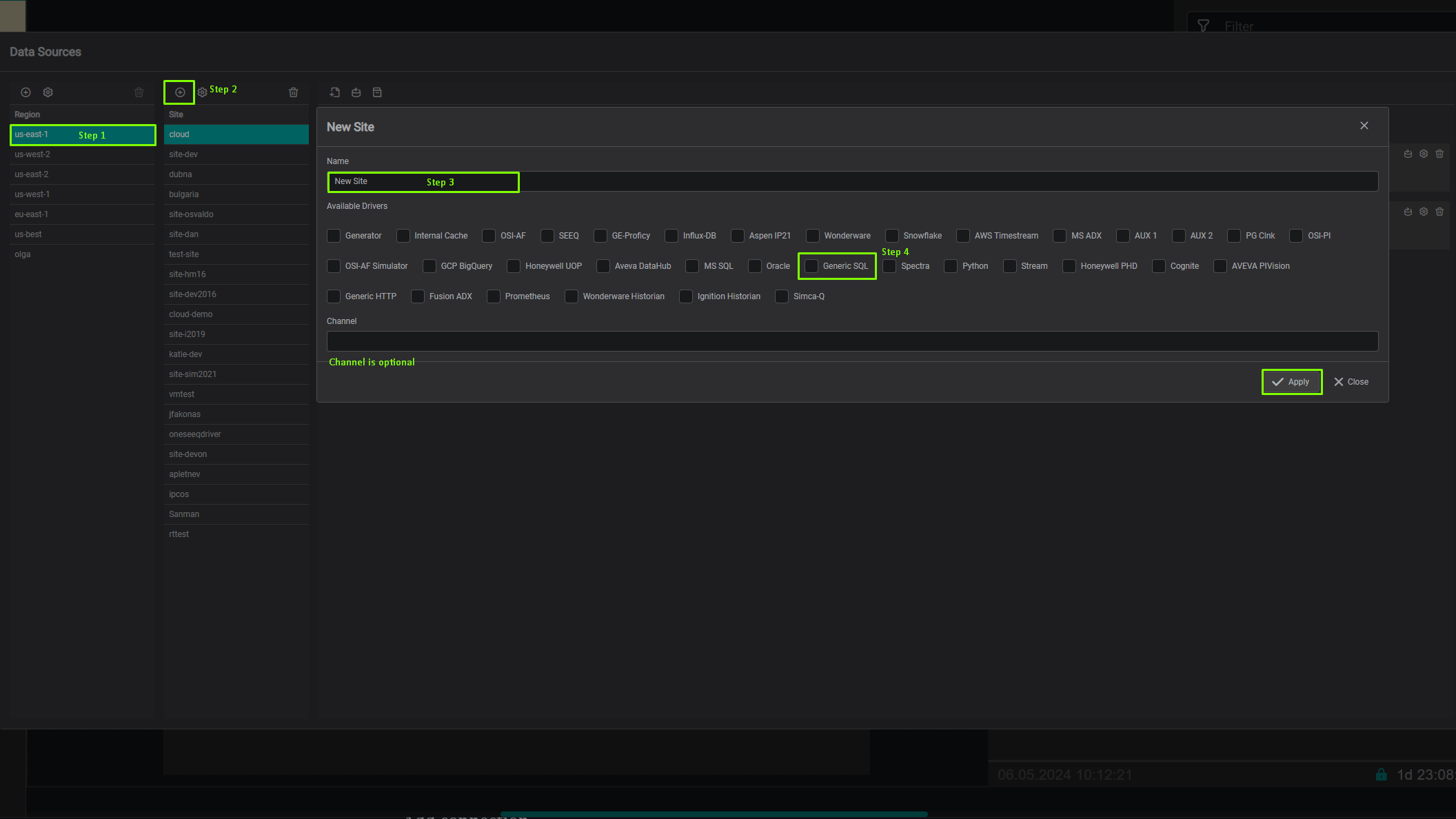
Add connection
The Databricks Driver container is automatically available in the IOTA Vue data sources section configured for specific
Region\Site.
Tips
The installer already contains all required configurations for specific Region\Site connectivity.
To add a new Databricks server connection navigate to data sources menu, then:
- Select region of interest
- Select the site of interest
- Select the tab named "GenericSQL" within the selected site.
- At the top right corner - click on the "Add" icon.
The Databricks Driver's connection dialog will appear.
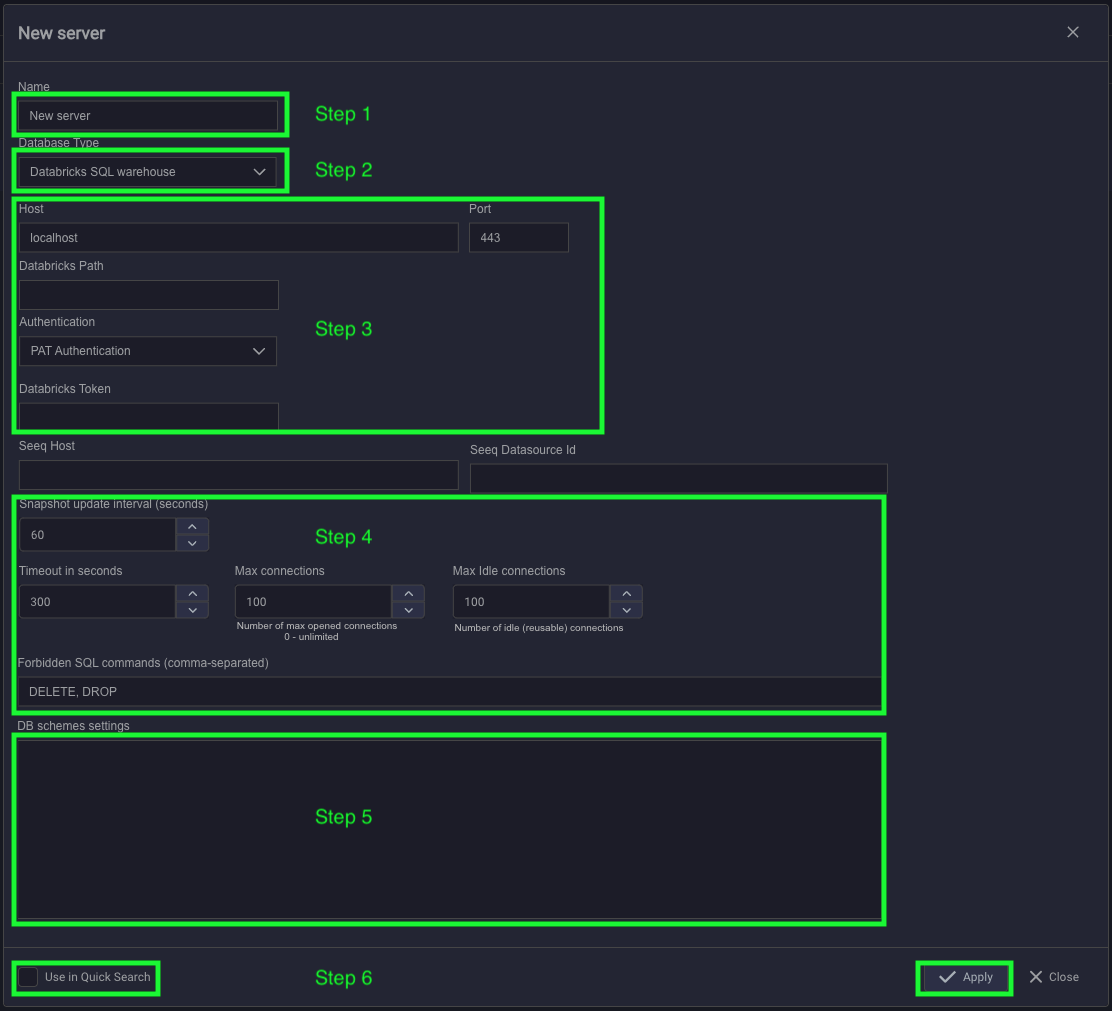
- Provide a name for the Connection to the database. All search results will be prefixed with this name
- Specify the database type.
- Specify the connection settings:
- Host should be like this: adb-3437785601138938.18.azuredatabricks.net
- Endpoint like this: /sql/1.0/warehouses/1d9459d7889d9b35
- Select Authentication type
- If Auth type is PAT - put your PAT token in Token field
- If Auth type is M2M - fill Client ID, Client Secret, and OAuth Endpoint fields
- Optional step, set a timeout variable. The variable is used for timeout exceptions between the Databricks Driver and
database server. - Specify the Database schema settings.
- Please check the "Use in Quick Search" checkbox if the Connection should be used in the quick search sidebar. If not
checked, the configured connection will only be available in Advanced search. - Click on the "Apply" to save changes.
If Connection has the "Use in Quick Search" checkbox selected, it becomes available in a quick search sidebar.
Driver Configuration
On every startup the Databricks Driver reads its configuration from the environment variables.
Tips
The Databricks Driver comes with a pre-configured environment. Therefore, manual configuration is not required.
Configuration parameters
| Environment name | Required | Default Value | Data Type | Description |
|---|---|---|---|---|
| DRIVERID | ⚫ | "" | string | Driver Id - used for logging purposes only |
| LOG_LEVEL | ⚫ | ERROR | string | Debug verbose level: ERROR, DEBUG, INFO |
| NATS_HOST | 🟢 | null | string | NATs server url with port |
| SEED_KEY_PATH | 🟢 | null | string | NATs NKey public key string. Private key must be defined in file: "privatekey.nk" |
| RQS_TOPIC | 🟢 | null | string | NATs topic on which driver listens for requests |
| HEALTH_TOPIC | ⚫ | "" | string | NATs topic for sending driver's health |
| HEALTH_SCHEDULING | ⚫ | 10000 | int | How often in milliseconds to send health data. Default: 10000 = 10 sec |
| LOGS_TOPIC | ⚫ | "" | string | NATs topic for sending driver's logs |
| METRICS_TOPIC | ⚫ | "" | string | NATs topic for sending driver's metrics |
| METRICS_SCHEDULING | ⚫ | 30000 | int | How often in milliseconds to send metrics data. Default: 30000 = 30 sec |
| ENABLE_METRICS | ⚫ | true | bool | Enables metrics reporting |
Database schema settings
This section provides instructions on how to configure the generic driver for data ingestion from SQL-like databases.
Settings are the JSON object described below
{
"tableSettings": [
{
"Id": string,
"Name": string,
"TimeColumn": string,
"TimeUnit": string,
"TimeLocation": string,
"TimeStringFormat": string,
"IntervalForSnapshotsInMin": int,
"DataColumns": []string,
"GroupBy": []string,
"LastGroupAsTagName": bool,
"TagProperties": JSON,
"SchemaName": string
}
],
"datasetTags": [
{
"name": string,
"query": string,
"parameters": JSON
}
],
"writeDataTags": [
{
"name": string,
"query": string,
"parameters": JSON
}
]
}tableSettings
This section describes the DB tables structure.
- Id, Name - (required) table name
- SchemaName - name of the schema stores table
- TimeColumn - (required) name of the column stores timestamp or datetime string
- TimeUnit - units of the time
- TimeLocation - a time location used by its name (e.g. "America/New_York"). TimeLocation is used to define a timezone used by your DB, by default it is UTC.
You can find a comprehensive list of time zone names in the IANA Time Zone
Database, which Go's time package uses. - TimeStringFormat - format of the datetime string. Used when the TimeColumn stores datetime as a string. The format is
described here Golang datetime string format - IntervalForSnapshotsInMin - minutes to narrow scanning a table, it is used for tabular data, if you know that your
columns are updated every day, you can specify it in this property, and the driver will build a query like give me a
snapshot in this range: now()-interval. Instead of give me snapshot order by time DESC, which scans the whole table.
This option will significantly improve the speed of the query. - DataColumns - (required) list of the columns names stores tag values
- GroupBy - list of the columns names stores asset tree. Used with Asset-Like and Metadata-Value tables
- LastGroupAsTagName - (required) flag represents is last element in the GroupBy list is tag name column
- TagProperties - map of the key-value pairs where key is one of ["uom", "description", "upbnd", "lobnd"] and value is
column name related to key tag property- uom - units of the tag measurement
- description - tag description
- upbnd - tag upper bound
- lobnd - tag lower bound
datasetTags
This section describes the custom queries to DB. These queries will be displayed in tag search.
- name - unique query name
- query - query string. May contain parameter placeholders
- parameters - map of the key-value pairs where key is the name of query parameter and value is the parameter value
See example of the configuration
writeDataTags
This section describes the custom INSERT|UPDATE|DELETE queries to DB.
- name - unique query name
- query - query string. May contain parameter placeholders
- parameters - map of the key-value pairs where key is the name of query parameter and value is the parameter value
The detailed configuration is described in the section Write data Tags
See example of the configuration
Reading Data from Tabular Tables
In statistics, tabular data refers to data organized in a table format with rows and columns. Consider the following
example of tabular data:
| ID | compressor_power | optimizer | relative_humidity | temperature | wet_bulb | ts |
|---|---|---|---|---|---|---|
| 0 | 0.0029228 | 0 | 62.35181596 | 79.64134287 | 70.29920291 | 2022-11-03 12:19 |
| 1 | 0.0029228 | 0 | 62.38810345 | 79.63862069 | 70.30710957 | 2022-11-03 12:20 |
| 2 | 0.0029228 | 0 | 62.4371127 | 79.63413962 | 70.31706517 | 2022-11-03 12:21 |
| 3 | 0.0029228 | 0 | 62.48612195 | 79.62965854 | 70.32702076 | 2022-11-03 12:22 |
Each column in this table represents a TAG. To configure the driver to read this data, use the following
configuration:
{
"Id": "tabular_data",
"Name": "tabular_data",
"TimeColumn": "ts",
"DataColumns": [
"compressor_power",
"optimizer",
"relative_humidity",
"temperature",
"wet_bulb"
],
"GroupBy": null,
"LastGroupAsTagName": false
}Configuration Details:
| Config Item | Description |
|---|---|
| Id | Unique ID used internally by the driver |
| Name | Name of the database's table |
| TimeColumn | Specifies the column containing the time series |
| DataColumns | Array of columns to convert into tags |
| GroupBy | Should be empty or null for tabular data |
| LastGroupAsTagName | Should be false for tabular data |
This configuration allows the driver to effectively handle and read tabular data from SQL-like databases.
Reading Data from Asset-like Tables
Additionally, data can be stored in the following table format:
| ID | ts | siteid | machineid | lineid | tag | value |
|---|---|---|---|---|---|---|
| 1 | '2022-11-03 21:27:47' | Site 1 | MachineA | Line 1 | Temperature | -47.43 |
| 2 | '2022-11-03 21:27:47' | Site 1 | MachineA | Line 1 | Pressure | 25.50 |
| 3 | '2022-11-03 21:27:47' | Site 1 | MachineA | Line 1 | Power | -14.03 |
| 4 | '2022-11-03 21:27:47' | Site 1 | MachineB | Line 1 | Temperature | 79.61 |
| 5 | '2022-11-03 21:27:47' | Site 1 | MachineB | Line 1 | Pressure | -27.63 |
| 6 | '2022-11-03 21:27:47' | Site 1 | MachineB | Line 1 | Power | 99.65 |
| 7 | '2022-11-03 21:27:47' | Site 1 | MachineC | Line 1 | Temperature | 32.08 |
| 8 | '2022-11-03 21:27:47' | Site 1 | MachineC | Line 1 | Pressure | 79.92 |
| 9 | '2022-11-03 21:27:47' | Site 1 | MachineC | Line 1 | Power | 162.36 |
| 10 | '2022-11-03 21:27:47' | Site 2 | MachineA | Line 1 | Temperature | 91.21 |
| 11 | '2022-11-03 21:28:47' | Site 2 | MachineB | Power | 38.12 | |
| 12 | '2022-11-03 21:41:47' | Site 1 | MachineB | Pressure | -27.70 |
This table structure can be represented as an asset tree:
- Site1
- Line 1
- MachineA
- Temperature
- Pressure
- Power
- MachineB
- Temperature
- Pressure
- Power
- MachineC
- Temperature
- Pressure
- Power
- MachineA
- Line 1
- Site2
- Line 1
- MachineA
- Temperature
- MachineB
- Power
- MachineA
- Line 1
The configuration for processing such table data is as follows:
{
"ID": "asset_tree_data",
"Name": "asset_tree_data",
"TimeColumn": "ts",
"DataColumns": [
"value"
],
"GroupBy": [
"siteid",
"lineid",
"machineid",
"tag"
],
"LastGroupAsTagName": true
}Configuration Details:
| Config Item | Description |
|---|---|
| Id | Unique ID used internally by the driver |
| Name | Name of the database's table |
| TimeColumn | Specifies the column containing the time series |
| DataColumns | Array of columns to convert into tags |
| GroupBy | An array that defines the hierarchy for creating the asset tree structure |
| LastGroupAsTagName | Should be true, as we want to show the 'value' column as the value of the last tag in the hierarchy |
Reading data From Metadata and Value Data
Sometimes data is stored in a dimension table and a fact table. This is a popular model choice because it allows
flexibility in the metadata (the dimension table) while allowing the value table (the fact table) to grow.
Metadata (Dimension Table)
| siteId | lineId | machineId | tag | tagId | unit | interpolation | valuetype |
|---|---|---|---|---|---|---|---|
| Site 1 | MachineA | Line 1 | Temperature | Site 1.Line 1.MachineA.Temperature123 | s | linear | numeric |
| Site 1 | MachineA | Line 1 | Pressure | Site 1.Line 1.MachineA.Pressure123 | megadonut/coffee | linear | numeric |
| Site 1 | MachineA | Line 1 | Power | Site 1.Line 1.MachineA.Power123 | ft/s | linear | numeric |
| Site 1 | MachineA | Line 1 | State_s | Site 1.Line 1.MachineA.State_s123 | step | linear | string |
| Site 1 | MachineA | Line 2 | Temperature | Site 1.Line 2.MachineA.Temperature123 | degC | linear | numeric |
Data (Fact Table)
| TS | tagId | valuetype | Value_S | Value_D |
|---|---|---|---|---|
| 2022-11-04T20:17:49 | Site 1.Line 1.MachineA.Temperature123 | numeric | 36.76654 | |
| 2022-11-04T20:17:49 | Site 1.Line 1.MachineA.Pressure123 | numeric | -214.179 | |
| 2022-11-04T20:17:49 | Site 1.Line 1.MachineA.Power123 | numeric | -33.6876 | |
| 2022-11-04T20:17:49 | Site 1.Line 1.MachineA.State_s123 | string | strval | |
| 2022-11-04T20:17:49 | Site 1.Line 2.MachineA.Temperature123 | numeric | 41.31567 | |
| 2022-11-04T20:17:49 | Site 1.Line 2.MachineA.Pressure123 | numeric | -87.6572 | |
| 2022-11-04T20:17:49 | Site 1.Line 2.MachineA.Power123 | numeric | 14.04372 | |
| 2022-11-04T20:17:49 | Site 1.Line 2.MachineA.State_s123 | string | strval |
The configuration for processing data from both tables is as follows:
{
"Id": "DataAndMetadata",
"Name": "Data",
"TimeColumn": "TS",
"TimeUnit": "",
"LastGroupAsTagName": true,
"DataColumns": [
"ValueD"
],
"GroupBy": [],
"ColumnId": "tagId",
"MetadataQuery": {
"TableName": "Metadata",
"Columns": [
"siteId",
"lineId",
"machineId",
"tag",
"unit",
"valuetype"
],
"UniqueKeyColumnName": "tagId",
"TagPropertiesMap": {
"Datatype": "valuetype"
}
}
}Configuration Details:
| Config Item | Description |
|---|---|
| MetadataQuery | A section related to mapping metadata with actual data |
| TableName | Name of the metadata table |
| Columns | Array of columns to convert into asset and tags |
| UniqueKeyColumnName | A key for joining two tables |
| TagPropertiesMap | A mapping for filling tag structure. See available options below. |
Mapping fields for TagPropertiesMap:
| Key | Description |
|---|---|
| Datatype | Map the data type of the tag to the column. If it's not specified, the type of the tag will be string. |
| Uom | Unit of measure for a tag; if not specified, the uom of a tag will be empty. |
| Upbnd | Upper limit |
| Lobnd | Lower boundary |
Virtual Tags (Datasets)
There are two options for executing custom SQL queries:
- Using a Query tag from Tags and Writing SQL Query Manually: This involves using the "Query from Tags" feature to
manually write your SQL query. - Using Virtual Tags with Hardcoded SQL: This option involves utilizing virtual tags that contain pre-defined SQL
queries.
For example, let's define a virtual tag in the configuration, named "DST2," with the following settings:
{
"name": "dst2",
"query": "SELECT * FROM tabular_data WHERE temperature > {{temp}} LIMIT 10",
"parameters": {
"temp": 10.0
}
}| Config Item | Description |
|---|---|
| Name | The name of the virtual tag. |
| Query | The SQL query that will be executed. It can contain specific arguments. |
| Parameters | A map of parameters that can be injected into the query. If this map is empty, the argument will be injected from the UI settings. |
Write Data Tags
{
"writeDataTags": [
{
"name": "addRecord",
"query": "INSERT INTO tabular_data (tsCol, valueCol) VALUES ({{tsCol}}, {{value}})",
"parameters": {
"timeColumn": "tsCol",
"tsCol": 0,
"value": 0
}
}
]
}Configuration example
Configure driver to connect to the database with tabular table tabular_data and asset-tree table asset_tree_data.
Additionally define virtual tag to receive temperature above 10 degrees.
{
"tableSettings": [
{
"Id": "tabular_data",
"Name": "tabular_data",
"TimeColumn": "ts",
"TimeUnit": "",
"DataColumns": [
"compressor_power",
"optimizer",
"relative_humidity",
"temperature",
"wet_bulb"
],
"GroupBy": null,
"LastGroupAsTagName": false
},
{
"ID": "asset_tree_data",
"Name": "asset_tree_data",
"TimeColumn": "ts",
"DataColumns": [
"value"
],
"GroupBy": [
"siteid",
"machineid",
"lineid",
"tag"
],
"LastGroupAsTagName": true,
"TagProperties": {
"uom": "units"
}
}
],
"datasetTags": [
{
"name": "GetTemperatureAbove10degrees",
"query": "SELECT * FROM tabular_data WHERE temperature > {{temp}} LIMIT 10",
"parameters": {
"temp": 10.0
}
}
],
"writeDataTags": [
{
"name": "addRecord",
"query": "INSERT INTO tabular_data (tsCol, valueCol) VALUES ({{tsCol}}, {{value}})",
"parameters": {
"timeColumn": "tsCol",
"tsCol": 0,
"value": 0
}
}
]
}Golang datetime string format
| Unit | Golang Layout | Examples | Note |
|---|---|---|---|
| Year | 06 | 21, 81, 01 | |
| Year | 2006 | 2021, 1981, 0001 | |
| Month | January | January, February, December | |
| Month | Jan | Jan, Feb, Dec | |
| Month | 1 | 1, 2, 12 | |
| Month | 01 | 01, 02, 12 | |
| Day | Monday | Monday, Wednesday, Sunday | |
| Day | Mon | Mon, Wed, Sun | |
| Day | 2 | 1, 2, 11, 31 | |
| Day | 02 | 01, 02, 11, 31 | zero padded day of the month |
| Day | _2 | ⎵1, ⎵2, 11, 31 | space padded day of the month |
| Day | 002 | 001, 002, 011, 031, 145, 365 | zero padded day of the year |
| Day | __2 | ⎵⎵1, ⎵⎵2, ⎵11, ⎵31, 365, 366 | space padded day of the year |
| Part of day | PM | AM, PM | |
| Part of day | pm | am, pm | |
| Hour 24h | 15 | 00, 01, 12, 23 | |
| Hour 12h | 3 | 1, 2, 12 | |
| Hour 12h | 03 | 01, 02, 12 | |
| Minute | 4 | 0, 4 ,10, 35 | |
| Minute | 04 | 00, 04 ,10, 35 | |
| Second | 5 | 0, 5, 25 | |
| Second | 05 | 00, 05, 25 | |
| 10-1 to 10-9 s | .0 .000000000 | .1, .199000000 | Trailing zeros included |
| 10-1 to 10-9 s | .9 .999999999 | .1, .199 | Trailing zeros omitted |
| Time zone | MST | UTC, MST, CET | |
| Time zone | Z07 | Z, +08, -05 Z is for UTC | |
| Time zone | Z0700 | Z, +0800, -0500 Z is for UTC | |
| Time zone | Z070000 | Z, +080000, -050000 Z is for UTC | |
| Time zone | Z07:00 | Z, +08:00, -05:00 Z is for UTC | |
| Time zone | Z07:00:00 | Z, +08:00:00, -05:00:00 Z is for UTC | |
| Time zone | -07 | +00, +08, -05 | |
| Time zone | -0700 | +0000, +0800, -0500 | |
| Time zone | -070000 | +000000, +080000, -050000 | |
| Time zone | -07:00 | +00:00, +08:00, -05:00 | |
| Time zone | -07:00:00 | +00:00:00, +08:00:00, -05:00:00 |