In order for IOTA Vue to access data on Google BigQuery - the IOTA BigQuery-Driver must be configured and deployed on network
which has access to required Google BigQuery. The IOTA Vue uses distributed "mesh-like" data source topology:
Users are free to define what Region and Site mean for their unique deployment.
| Name | Example | Description |
|---|---|---|
| Region | us-east-1 | geographical territory, similar to availability regions |
| Site | siteB | specific plant or a building |
To simplify the installation process, the IOTA Software provides a container image with the latest driver version. The
user is only required to select/create a region and site. Then for the selected driver type, click add a new server.
The container contains all necessary BigQuery-Driver configurations with public and private keys for secure communication
with the company's IOTA Vue NATs message bus.
To Access the Data Sources menu, click at the top right corner on the "hamburger" icon, then select "Data Sources".
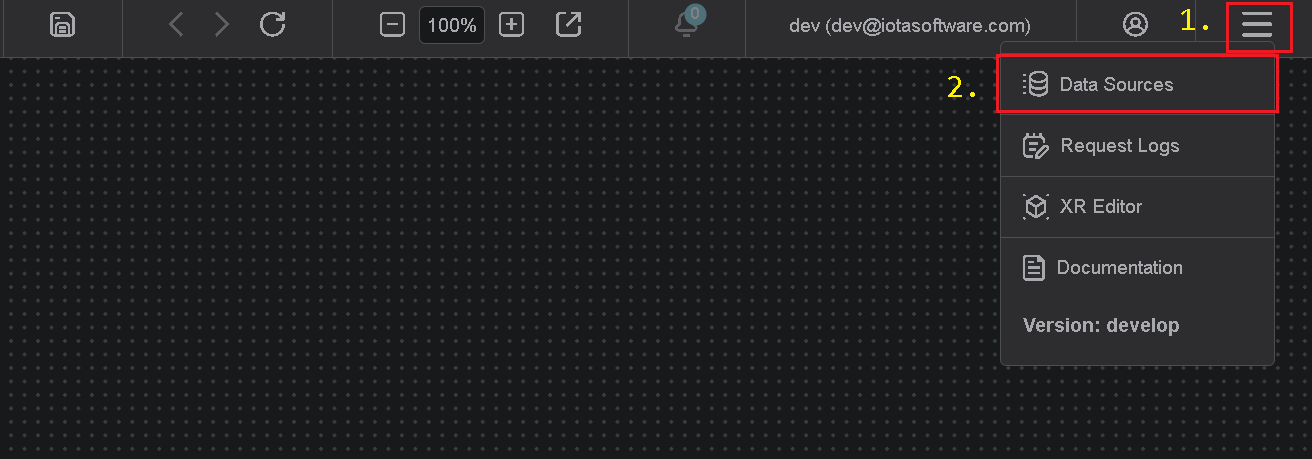
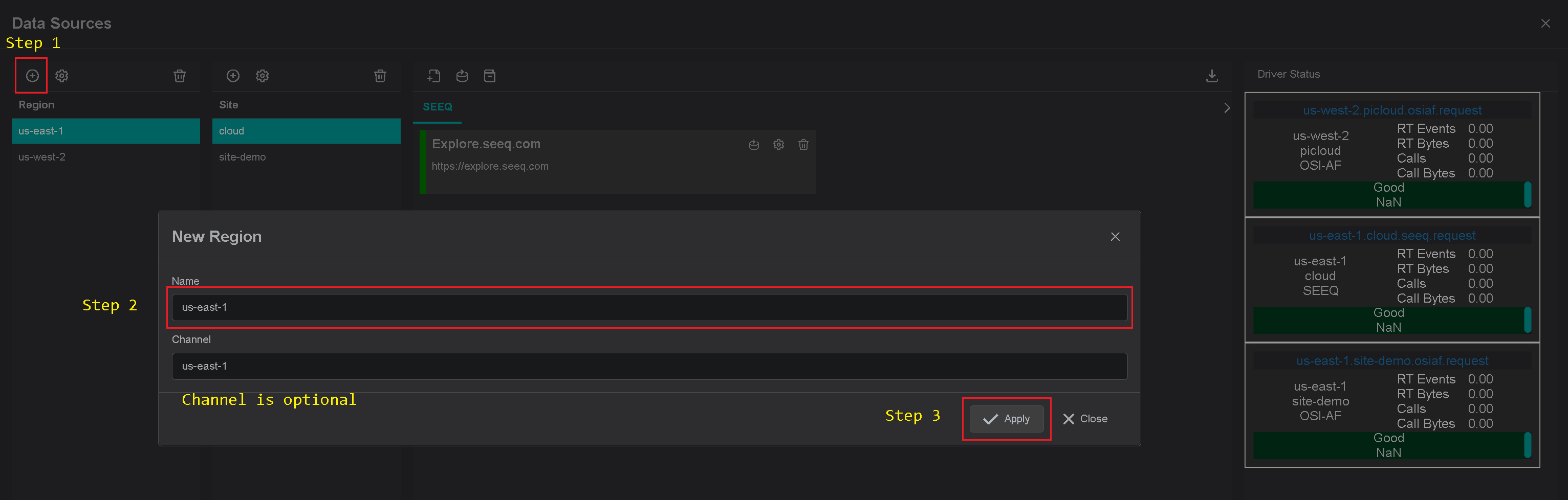
Add Region
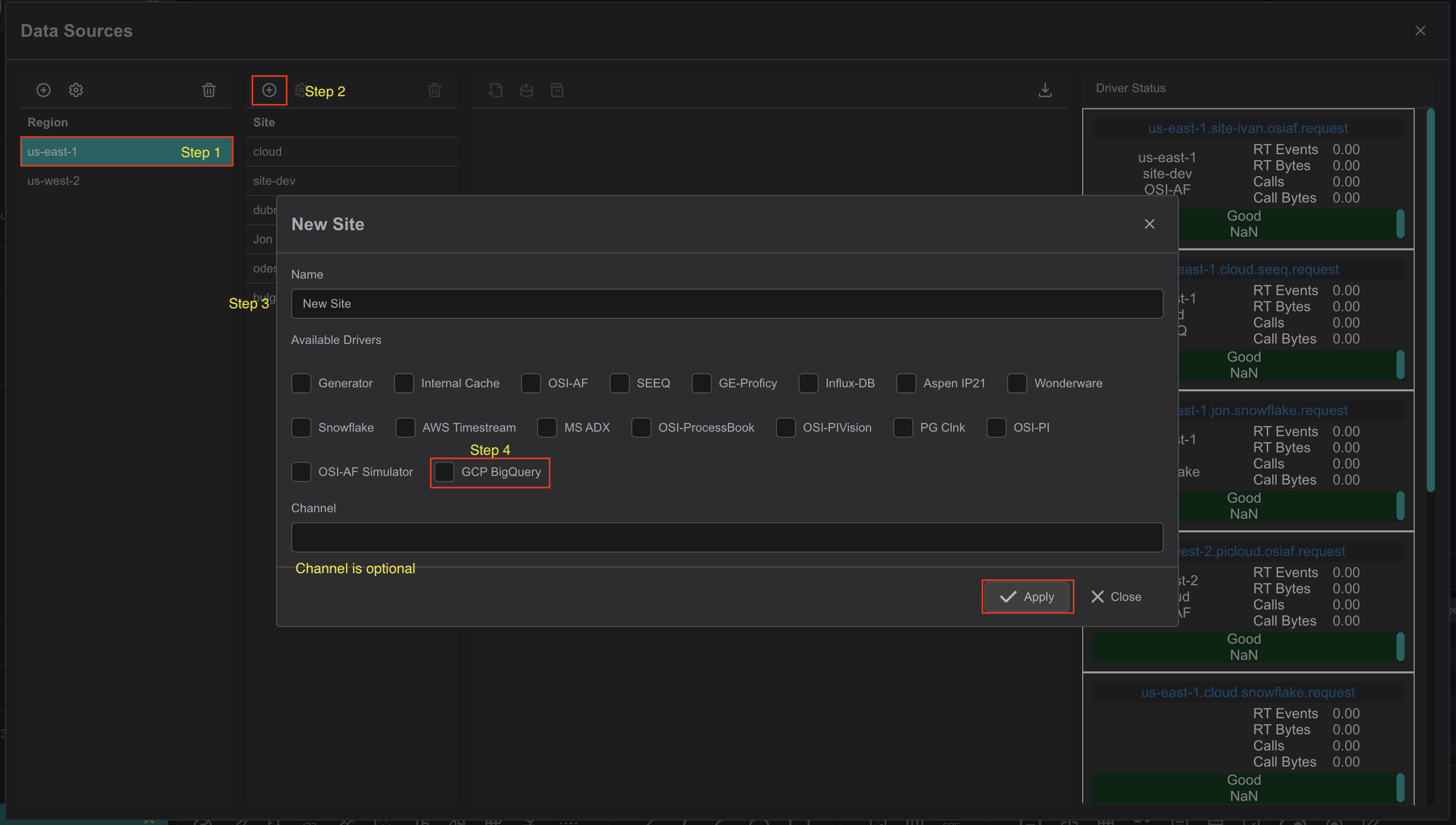
Click on the "Add" icon to add a new site, then in the popup dialog - enter the site name. Make sure the GCP BigQuery checkbox
is selected. Each site can contain multiple driver types. For each checked driver type - the instance pane will contain
selected driver tabs to which connection instances can be added.
There are two input fields:
- Site name
- Channel name (optional)
The site name is a user-friendly name, and the channel name can contain abbreviations. If the channel name is not
provided, it is automatically assigned to the site name on the "Apply" button click.
Add Site
Click on the "Add" icon to add a new site, then in the popup dialog - enter the site name. Make sure the GCP BigQuery checkbox
is selected. Each site can contain multiple driver types. For each checked driver type - the instance pane will contain
selected driver tabs to which connection instances can be added.
There are three input fields:
- Site name
- Driver type
- Channel name (optional)
The site name is a user-friendly name, and the channel name can contain abbreviations. If the channel name is not
provided, it is automatically assigned to the site name on the "Apply" button click.
Add connection
The BigQuery-Driver container is automatically available in the IOTA Vue data sources section configured for specific
Region\Site.
Tips
The installer already contains all required configurations for specific Region\Site connectivity.
To add a new BigQuery connection navigate to data sources menu, then:
- Select region of interest
- Select the site of interest
- Select the BigQuery Driver tab named "GCP BigQuery" within the selected site.
- At the top right corner - click on the "Add" icon.
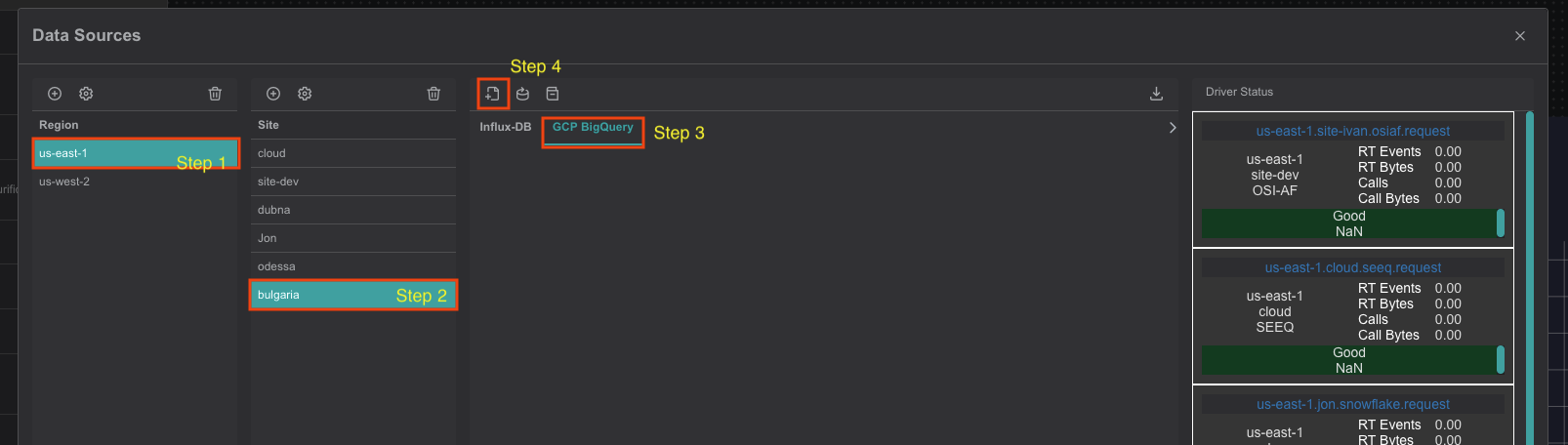
The BigQuery-Driver's connection dialog will appear.
- Provide a name for the BigQuery Connection. All search results will be prefixed with this name
- See the link for more information
- Fill all fields from Google's provided service accounts JSON fields
To setup Authentication in Google, you can use a next article - Fill table mapping configuration see Configuring a connection, see the next link for more information
- Please check the "Use in Quick Search" checkbox if BigQuery Connection should be used in the quick search sidebar.
The configured connection will only be available in Advanced search if not checked. - Click on the "Apply" to save changes.
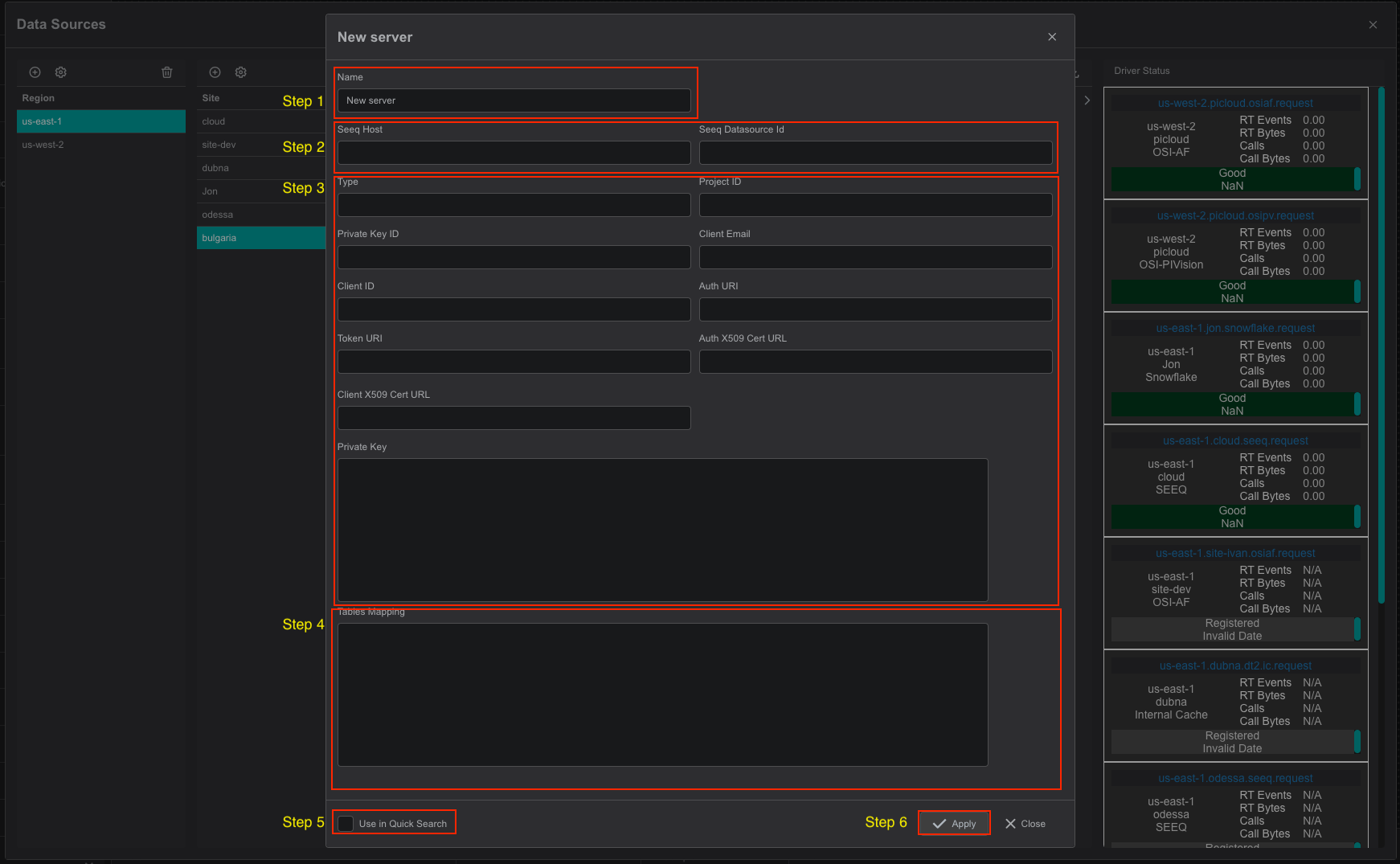
If BigQuery Connection has the "Use in Quick Search" checkbox selected, it becomes available in a quick search sidebar.
Configuring a connection
Configuration example:
{
"Id": "cf4e24bd-5771-495c-9a8b-9bcb1446e4e8",
"Name": "data_by_province",
"GroupBy": [
"country",
"name",
"province_name"
],
"DataColumn": {
"Name": "confirmed_cases",
"Type": "int64"
},
"TimeColumn": "date",
"ProjectId": "bigquery-public-data",
"DataSet": "covid19_italy"
}A table configuration maps BigQuery tabular data into Driver's specific data types such as Tags and Assets.
- Id: Unique ID for the table configuration itself.
- ProjectId: BigQuery project name. Example: "ProjectId" : "bigquery-public-data"
- DataSet: BigQuery dataset name. Example: "DataSet" : "covid19_italy"
- Name: BigQuery table name. Example: "Name" : "data_by_province"
- GroupBy: Column collection which allows to group data through building the asset hierarchy based on distinct column value combinations.
The column name order is important; it is used to generate the asset hierarchy. Example: "GroupBy" :[ "country", "region_name", "province_name" ]
parameter definition produces the following hierarchy:<country>\<region_name>\<province_name>.
When GroupBy is provided - the associated tag collection is linked to the asset defined by the GroupBy leaf element.
When GroupBy parameter is not provided - the tag collection is linked to the asset representing BigQuery table. - DataColumn: The column which data field used as a tag value in the IOTA Vue. Also important to pass a column type, the driver supports: Int64, Float64, and String
- TimeColumn: The column used as the timestamp source. Example: "TimeColumn" : "starttime"
Seeq Integration
The IOTA Vue provides seamless integration with Seeq Workbench.
Every single object in IOTA views can be used to push its data channels to Seeq for advanced analytics.
Since Seeq and IOTA Vue use different data querying approaches, the mapping is required to bind IOTA Vue PI Data Archive tags to Seeq signals.
The driver requires a Seeq Url with a port number and datasource id, which you can find in the Seeq Administration panel.
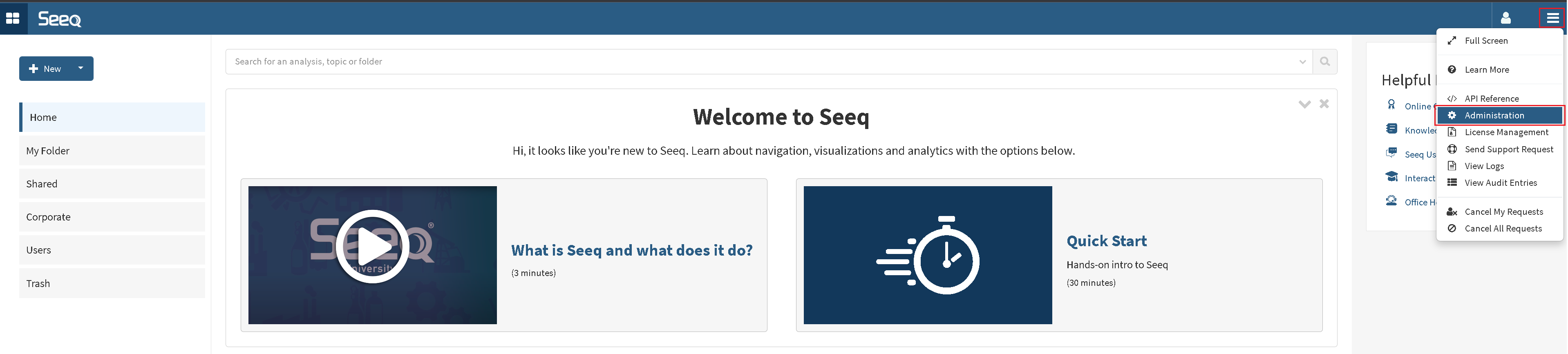
In Administration panel:
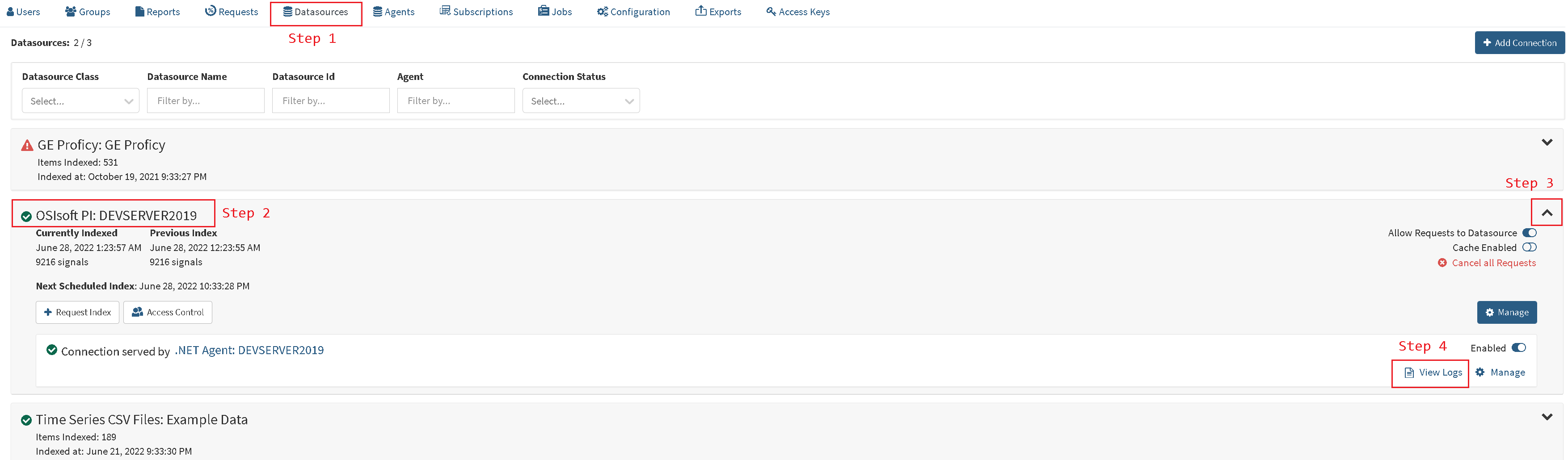
- Select "Data Sources" tab
- Locate the PI Data Archive which corresponds to our PI Data Archive name or IP.
- Expand PIConnector configuration by clicking on expand icon
- Open PIConnector logs dialog
On the Logs page the data source Id can be taken from
- Filter box
- Any message on the screen
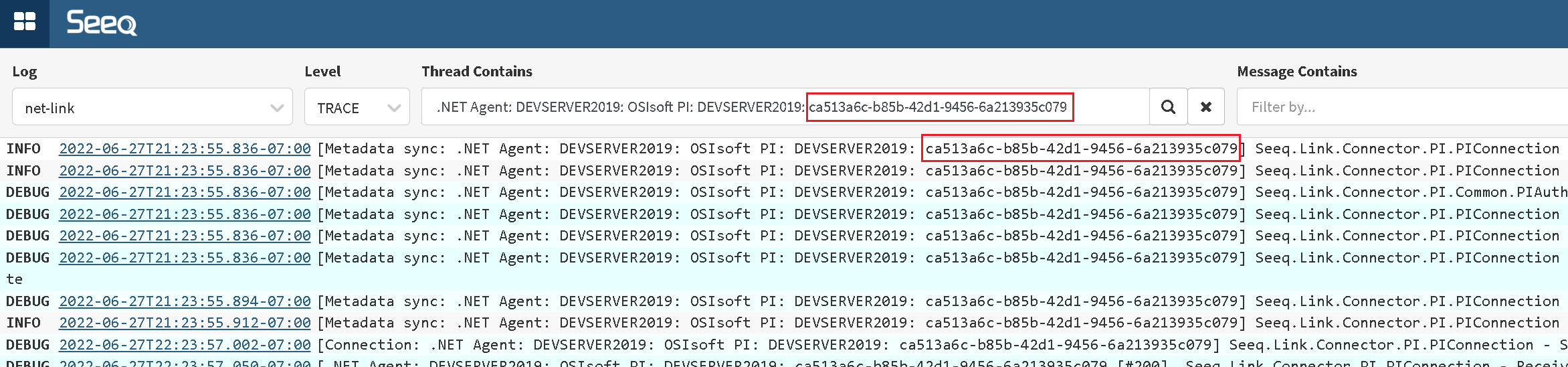
Copy and assign the guid in the connection instance dialog
Driver Configuration
On every startup the BigQuery-Driver reads its configuration from the environment variables.
Tips
The BigQuery-Driver comes with a pre-configured environment. Therefore, manual configuration is not required.
Configuration parameters
| Environment name | Required | Default Value | Data Type | Description |
|---|---|---|---|---|
| DRIVERID | ⚫ | "" | string | Driver Id - used for logging purposes only |
| LOG_LEVEL | ⚫ | ERROR | string | Debug verbose level: ERROR, DEBUG, INFO |
| NATS_HOST | 🟢 | null | string | NATs server url with port |
| SEED_KEY_PATH | 🟢 | null | string | NATs NKey public key string. Private key must be defined in file: "privatekey.nk" |
| RQS_TOPIC | 🟢 | null | string | NATs topic on which driver listens for requests |
| HEALTH_TOPIC | ⚫ | "" | string | NATs topic for sending driver's health |
| HEALTH_SCHEDULING | ⚫ | 10000 | int | How often in milliseconds to send health data. Default: 10000 = 10 sec |
| LOGS_TOPIC | ⚫ | "" | string | NATs topic for sending driver's logs |
| METRICS_TOPIC | ⚫ | "" | string | NATs topic for sending driver's metrics |
| METRICS_SCHEDULING | ⚫ | 30000 | int | How often in milliseconds to send metrics data. Default: 30000 = 30 sec |
| ENABLE_METRICS | ⚫ | true | bool | Enables metrics reporting |